HANA C++ Development Environment and Processes
2017-12-08 · C++ · Programming · WorkI started working as a C++ developer in the HANA Core Platform team at SAP in Walldorf, Germany more than a year ago. In this time I have gotten some insights into the development environment and processes. I will use this post to illustrate them by the example of adding a small new feature and explaining the steps on the way of getting it released. Some of this will be specific to HANA, some to my team inside HANA, some to my own system.

Compilation
HANA is the in-house database powering many of SAP’s products. It is written in C++ with Python tests, and the entire code base lives inside of a single git repository. Hundreds of developers from all around the world are developing on about 10 million lines of C++ code and 15 million lines of Python tests.
Since HANA is deployed on Linux exclusively, many developers are using Linux on their workstations as well. So far Windows is still supported as a development environment, but this will change in 2019, leaving Linux as the only choice. During day-to-day work you still get to interact with Windows a bit (more than I would prefer), since the Laptop has Windows with the traditional Microsoft Office products on it. But since the actual development happens on Linux, I am happy enough, being able to use the xmonad window manager and software environment I have gotten used to over the last decade.
HANA is deployed on some rather impressive machines, so in order to test the code adequately the developer workstations are quite beefy as well. I am typing this text from a 20 core / 40 thread Xeon E5-2660 v3 CPU with 128 GB of RAM.
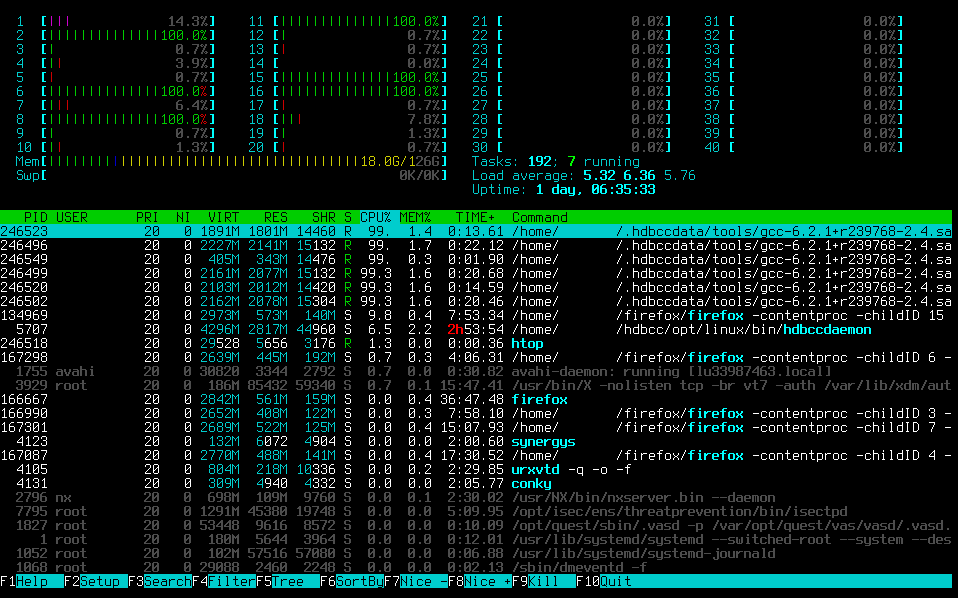
Still compiling HANA is no quick feat. Expect something around 2 hours to build it from scratch on your local machine (illustrated below), and be prepared for some heat output, which is especially noticeable in summer. About half of the colleagues have chosen to move their workstations to the data center and access it remotely instead of working on it locally. Since they are still in one of our SAP buildings in Walldorf, the latency is low enough that a direct X connection is fast enough to be nearly undistinguishable from a local application.
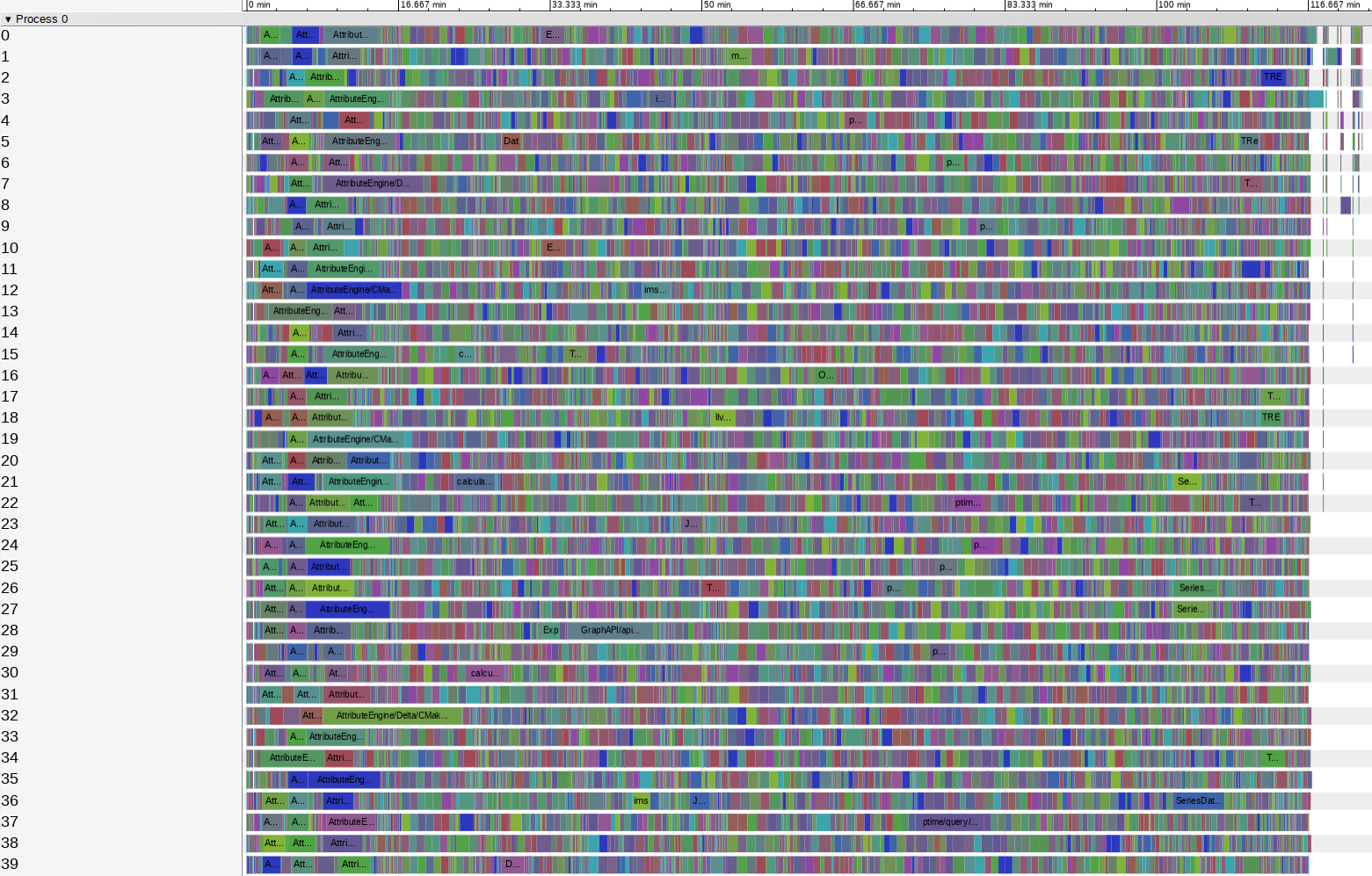
So if even your beefy developer machine is not enough, how do you compile the product faster? Obviously by combining all of the developer machines together in a compile cluster:
Using the compile cluster the build time gets reduced to 16 minutes and now linking takes half of that time. Right now we are still using the gold linker, but after bug fixes lld should cut down the linking time significantly.
Coding
But for the code in my team we have another approach. Instead of running the full database and testing using Python tests we have extensive unit tests, literally covering our entire code. Every single line is covered and about 98% of all regions. In order to submit any new code you have to write a unit test that will cover this exact code and include it in the same change.
Expect 5 minutes to build and run the unit tests from scratch, while building and running them after a change can be as fast as 15 seconds if you didn’t change much and thus not much has to be recompiled.
People use quite a variety of IDEs and code editors, with Sublime Text, Qt Creator, Eclipse, Visual Studio, emacs and vim being popular choices (in no particular order). Personally I like to work directly on terminals, so I use vim with the YouCompleteMe semantic code completion (and go to definition, type analysis and some more) based on clang/llvm. I use a custom YCM version which also shows me the size and alignment of a variable along with its type:
plangen::PipelineBuilder & => hex::plangen::PipelineBuilder & (size: 128 B, align: 16 B)
Using vim and other command line tools gives me the advantage that I can work just fine as long as I have an SSH connection to my workstation, nothing else required.
Let’s start by coming up with a useful new feature, tracing the name of the DummyNoRun operator:
#pragma once
#include "hex/planex/framework/OperatorBases.hpp"
#include "hex/planex/planviz/HasReversedConnection.hpp"
#include "warnings/clang_warnings_hard.h"
#include "warnings/gcc_warnings_veryhard.h"
namespace hex {
namespace operators {
class DummyNoRunOp final
: public planviz::HasReversedConnection,
public planex::NoRunOperator
{
void traceOperatorName(ltt::ostream& os) const;
};
} // namespace operators
} // namespace hex
#include "warnings/clang_warnings_end.h"
#include "warnings/gcc_warnings_end.h"The implementation is quite simple as well:
void DummyNoRunOp::traceOperatorName(ltt::ostream& os) const
{
os << "DummyNoRunOp";
}For HANA development we use C++14 at this moment. The only unusual thing is that we don’t use the STL, but instead have our own implementation of it, the LTT, which enforces allocator use.
Our build system wraps around cmake, so it is quite reasonable to use. After adding the cpp file to CMakeLists.txt we can locally run our unit tests and verify that nothing broke so far.
But when we’re compiling the code with hm b -b Optimized unitHexOperators (read as: HappyMake build Optimized build [with optimizations and assertions] of the unitHexOperators target) we get an unexpected result:
In file included from ../../hex/plangen/PredInitOpGenerator.cpp:14:0:
../../hex/operators/table/DummyNoRunOp.hpp:16:10: error: ‘virtual void hex::operators::DummyNoRunOp::traceOperatorName(ltt::ostream&) const’ can be marked override [-Werror=suggest-override]
void traceOperatorName(ltt::ostream& os) const;
^~~~~~~~~~~~~~~~~
cc1plus: all warnings being treated as errors
ERROR: subcommand failed
Our warning levels are quite high and all warnings are converted to errors. We even enable warnings in headers (and disable them again at the end in order to not affect other headers that might be included later). In this case the fix is quite simple:
void traceOperatorName(ltt::ostream& os) const override;Now our code builds and the unit tests succeed:
$ hm b -b Optimized runtests_hex
...
[==========] 728 tests from 147 test cases ran. (11617 ms total)
[ PASSED ] 728 tests.
YOU HAVE 2 DISABLED TESTS
Build started: 2017-11-29 16:26:40.459482
Build finished: 2017-11-29 16:26:52.988541
Elapsed time: 12.529s
Command count: 11 (0.9 per sec)
Log directory: /home/dXXXXXX/src2/build/Optimized/hm_log/build/24
SUCCESS
We can also run the code coverage based on our unit tests locally using CheckBot. Unsurprisingly we will find out that our code is not covered yet:
###############################################################
CheckBot - Review Details
###############################################################
###############################################################
CheckBot - Summary
###############################################################
______________
General Issues
______________
[CheckHexCodeCoverageClang] (error) hex/operators/table/DummyNoRunOp.cpp: 3 of 3 lines uncovered, 0.00% coverage!
[CheckHexCodeCoverageClang] (error) Line coverage only at 99.99%
[CheckHexCodeCoverageClang] (info) Coverage report can be found at
file://///home/dXXXXXX/src2/build/linuxx86_64-clangcov-release_hex_with_code_coverage/hexCoverageClang/index.html
CheckBot detected 3 issues (2 errors, 1 info).
error ... CheckHexCodeCoverageClang (681748.81 msec)
Overall score: -2
(Legend: ok = +1, info = +1, warning = -1, error = -2)
At the bottom of the report we see the “Overall score: -2”, which indicates that our change would not be allowed to be merged by Gerrit. So let’s take a closer look, inside of the linked report we find our code:
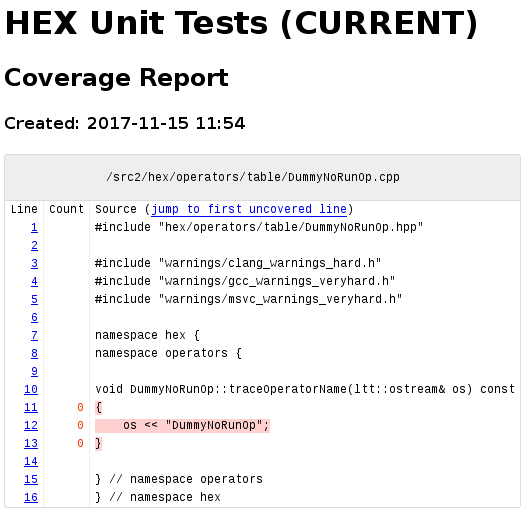
Google Test/Mock based unit tests are used to test every part of the code in our team. 100% unit test line coverage is achieved with a development version of llvm-cov. Compared to the gcc based gcov/lcov coverage tools, the LLVM based llvm-cov is in active development, runs much faster and can show you what region of a line is actually covered, allowing finer granularity.
So let’s write a unit test to satisfy the 100% line coverage requirement:
#include "hex/operators/table/DummyNoRunOp.hpp"
#include "hex/test/HexTestBase.hpp"
#include "hex/planex/test/sandbox/SimpleOperatorSandbox.hpp"
#include "warnings/clang_warnings_hard.h"
#include "warnings/gcc_warnings_hard.h"
#include "warnings/msvc_warnings_hard.h"
using namespace ::testing;
namespace hex {
namespace operators {
namespace test {
class UnitDummyNoRunOp : public HexTestBase<>
{
protected:
planex::SimpleOperatorSandbox<DummyNoRunOp> m_sb{alloc()};
ltt::ostringstream m_oss{alloc()};
};
TEST_F(UnitDummyNoRunOp, traceOperatorName)
{
m_oss << planex::Operator::TraceName{m_sb.op()};
EXPECT_THAT(m_oss.c_str(), StrEq("UnitDummyNoRunOp"));
}
} // namespace test
} // namespace operators
} // namespace hexFor more coarse-grained testing there are also JSON based component tests as well Python based integration tests available.
Local Verification
We should also make use of some static code checkers, like clang-format and clang-tidy, before we push the change for remote testing. After all, this ensures a consistent style, fixes some common problems and reduces the mental load on the manual reviewers, since they can rely on the tools instead of complaining about the same trivial nitpick on every change:
###############################################################
CheckBot - Review Details
###############################################################
_____________________________________________
hex/operators/table/test/UnitDummyNoRunOp.cpp
_____________________________________________
[CheckClangFormat] (info) This file is subject to a clang-format code style. CheckBot can reformat the file, see [...]
line 2,0 - 2,35:
#include "hex/test/HexTestBase.hpp"
^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
[CheckClangFormat] (warning)
#include "hex/test/HexTestBase.hpp"
should be deleted
line 3,0 - 3,0:
#include "hex/planex/test/sandbox/SimpleOperatorSandbox.hpp"
^
[CheckClangFormat] (warning)
#include "hex/test/HexTestBase.hpp"
should be added
Luckily clang-format can even fix the problem on its own by just adding a parameter.
Remote Verification
Finally we can push the change to Gerrit. Now our local work is done and we can start working on something else. Meanwhile automated builds and tests will happen on Linux and Windows machines, as well as a coverage run and various static code analyzers (that we were too lazy to run locally).
By default just our unit tests and component tests are compiled and executed. But if you want to build the full HANA database and run the Python tests a separate profile is available for that and can be turned on in the Gerrit web interface for specific changes.
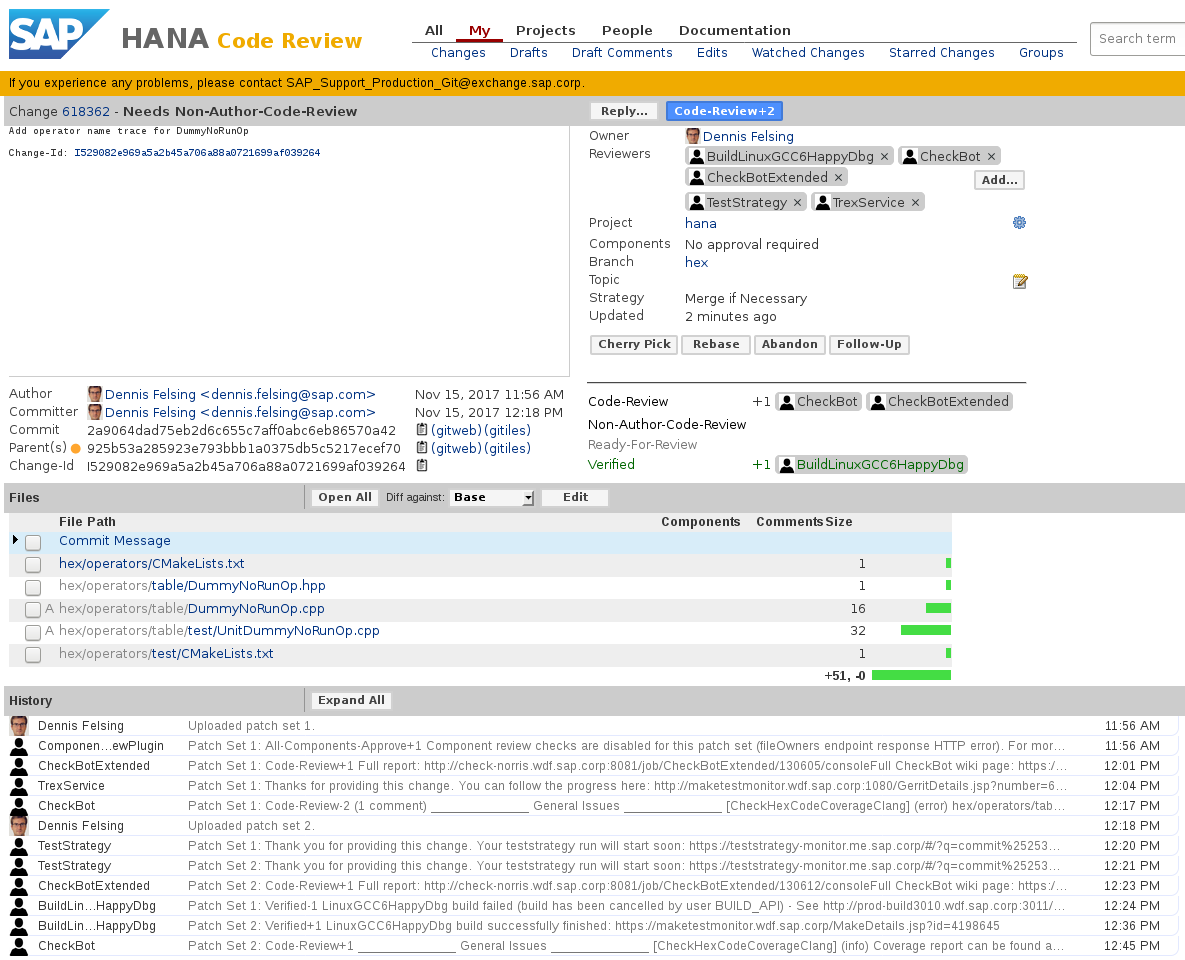
Code Review
Once we have verified that everything works fine on Linux with GCC and Clang as well as Windows with MSVC, we can add a reviewer to our change and set the change to “Ready for Review”. A second reviewer will be chosen automatically. If you are relatively sure that your change will survive the tests and don’t feel like waiting for them, you can of course also add the reviewers straight after submitting the change. But your reviewers might not be happy if they start reviewing already and meanwhile you are pushing new patch sets to fix compilation, tests as well as automatic warnings and suggestions.
For non-trivial changes further patch sets would follow to integrate the suggestions by the reviewers, until everyone is (reasonably) happy. Finally the change can be submitted and is out of our mind.
Merging
Except that there is still one thing missing. Our change is now inside of our component’s hex branch, but not yet in the global orange branch. The merge from hex to orange will run a huge number of correctness and performance tests before allowing our changes in. That’s why we only run it after we have collected a few changes. We also use a staging branch hex2orange.
- Initially we merge the
hexbranch intohex2orangeand try to mergehex2orangeintoorange. - Meanwhile everyone can keep developing new features as well as bug fixes on the
hexbranch. - If the merge from
hex2orangetoorangefails, a fix for the issue will be submitted tohexand can finally be cherry-picked tohex2orange.
But we don’t merge hex into hex2orange again, until we landed in the orange branch. Otherwise the new features from hex could cause new test failures while we were fixing the old ones. In the worst case we would never reach orange.
Once the colleagues give a green light on all tests, the merge goes in and we can sit and wait for bugs for our new feature to roll in.
Conclusion
I hope you found something interesting in this post. On a related note, SAP HANA is hiring right now in a few locations.
Discuss on Hacker News and r/programming.